İstatistiksel analizler için gerekli modüller: scipy.stats, scipy.optimize, numpy. Yardımcı modüller ise matplotlib.pyplot, pandas, seaborn.
İstatistikteki Tanımlar
Popülasyon (Population): Bir nesnenin tüm özelliklerini belirlemek için seçilen örneklerdir.
Örneklem (Sample): Bir nesnenin özelliklerini belirlemek için seçilen örneklerdir.
Belirsizlik (Uncertainty): Örneklem veya popülasyonun özelliklerini belirlemek için kullanılan örneklerin sayısının yetersiz olmasıdır.
Veri (Data): Bir araştırma veya analiz için toplanan sayısal veya kategorik bilgilerdir.
Ortalama (Mean) : Veri setinin tüm değerlerinin toplamının, veri setindeki eleman sayısına bölünmesiyle elde edilir.
Medyan veya Ortanca Değer (Median): Veri setindeki değerlerin ortalamasına göre sıralandıktan sonra ortadaki değerdir.
Mod veya Tepe Değer (Mod): Veri setindeki en sık tekrar eden değerdir.
Varyans (Variance) : Veri setindeki değerlerin ortalama değere ne kadar dağıldığını ölçen bir istatistiksel ölçüdür.
Standart Sapma (Standard Deviation): Veri setindeki değerlerin ortalama değerden ne kadar sapma gösterdiğini gösteren bir ölçüdür.
Çeyrekler (Quartiles): Veri setindeki değerlerin sıralanmasından sonra ortadaki değer orta çeyreklik, orta çeyreklik ile en küçük değerin ortasındaki değer alt çeyreklik (%25), orta çeyreklik ile en büyük değerin ortasındaki değer üst çeyreklik (%75) olarak tanımlanır.
Minimum ve maksimum değer (Minimum and Maximum): Veri setindeki en küçük ve en büyük değerlerdir.
Dağılımlar
Dağılımları anlamak için aşağıdaki karakteristik özelliklere bakabiliriz.
Merkezi eğilim (Central tendency): Dağılımın bir merkezi var mı?
Modlar: En sık tekrar eden değerler dağılımda nasıl gözüküyor?
Yayılım (Spread): Dağılımın merkezden uzağa doğru nasıl yayılmış? Simetrik mi?
Kuyruklar (Tails): Dağılımın kuyruklarında nasıl bir dağılım var?
Aykırılar (Outliers): Dağılımın kuyruklarında “aykırı” değerler var mı? Veriyi nasıl etkiliyorlar?
Ortalama değer (aritmetik ortalama) aşağıdaki formül ile hesaplanır.
Örneklem uzayı kullanılıyorsa, payda \(n-1\), popülasyon kullanılıyorsa payda \(n\) olmalıdır.
Örneğin bir veri setinde ortalama hamilelik süresi \(38.6\) olsun. Bu değerin standart sapması \(2.7\) olarak elde edilsin. Bu da demek oluyor ki gebelik süresi \(38.6 \mp 2.7\) şeklinde söyleyebiliriz.
Histogramlar, veri setlerinin dağılımlarını görselleştirmek için kullanılır. Histogram ile yapılan görsellerde, veri setlerinin merkezi eğillerini, modunu, yayılımını ve kuyruklarını görebiliriz. Ayrıca histogramlar, veri setlerindeki aykırı değerleri belirlemek için de kullanılır.
Efektif Boyut
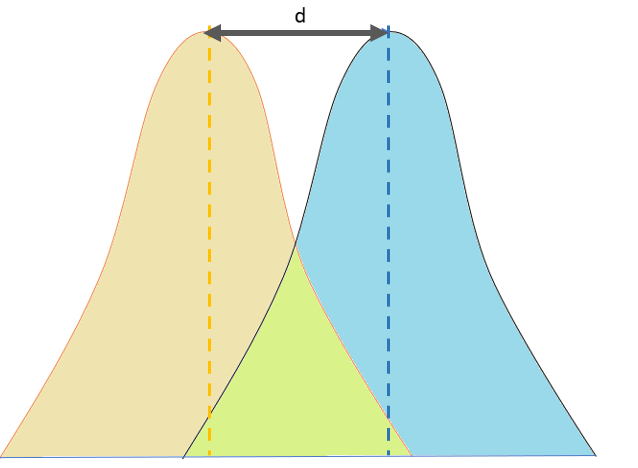
Bir popülasyonda veya örneklemde, iki değişken arasındaki ilişkinin gücünü vermek için Cohen’in d değeri tanımlanır. Ayrıntılı bilgi için referanslara bakın.
\[
d = \frac{\overline{x}_1 - \overline{x}_2}{s_{havuz}}
\]
Burada \(\overline{x}_1\) birinci grubun ortalaması, \(\overline{x}_2\) ikinci grubun ortalaması ve \(s_{havuz}\) ise grupların ortak havuz standart sapmasıdır (pooled standard deviation). \(s_{havuz}\) aşağıdaki gibi tanımlanır.
Burada \(n1\) ve \(n2\) grupların örneklem sayısı, \(s1\) ve \(s2\) grupların standart sapmasıdır.
Cohen’in d değeri
Alıştırma 1
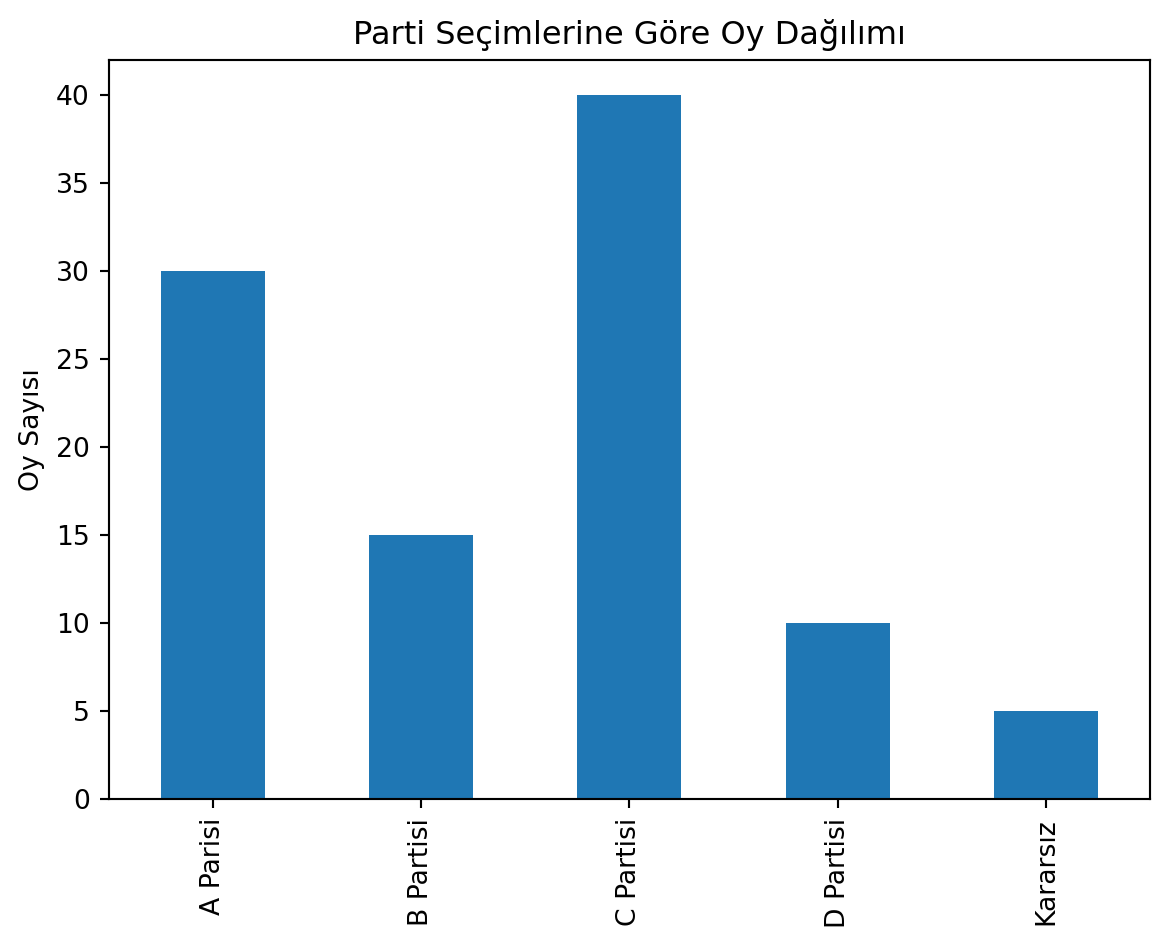
Bir araştırmada seçimlerdeki oy dağılımı tahmin edilmek istenmektedir. Toplamda 1000 kişi oy vereceğini düşünelim. Anket şirketi de 100 kişiye sormuş. Bu 100 kişinin oy dağılımı şu şekilde:
A Partisi
B Partisi
C Partisi
D Partisi
Kararsız
30
15
40
10
5
Çözüm
import pandas as pdimport numpy as np# Veri setidf= pd.Series({'A Parisi':30,'B Partisi':15,'C Partisi':40,'D Partisi':10,'Kararsız':5})# Çizdf.plot(kind='bar', title='Parti Seçimlerine Göre Oy Dağılımı', ylabel='Oy Sayısı')# Pandas açıklamaprint(df.describe())
count 5.00000
mean 20.00000
std 14.57738
min 5.00000
25% 10.00000
50% 15.00000
75% 30.00000
max 40.00000
dtype: float64
Yukarıdaki tanımlara doğrultusunda alıştırmayı tekrar ele alalım.
Popülasyon: 1000 (Tüm nüfus)
Örneklem: 100 (Anket yapılan kişi sayısı)
Örneklem Adeti: 1 (Kaç kere anket yapıldığı, 1 şirket)
Belirsizlik: 900 (Kime oy vereceği bilinmeyen kişi sayısı)
Veri: 100
30 A Partisi, 15 B Partisi, 40 C Partisi, 10 D Partisi, 5 Kararsız
Veri: 21,22,20,18,19
Varyans (Veri-Ortalamaya-Yakın): 2.0
Standart Sapma (Veri-Ortalamaya-Yakın): 1.4142135623730951
--------------------
Veri: 30,15,40,10,5
Varyans: 170.0
Standart Sapma: 13.038404810405298
pandas içerisinde describe() fonksiyonu ile belirlenen değerleri numpy paketi ile de belirleyebiliriz.
import numpy as npveri= np.array([30., 15., 40., 10., 5.])print("Veri: 30,15,40,10,5")print(f"Ortalama: {veri.mean()}")print(f"Varyans: {veri.var()}")print(f"Standart Sapma: {veri.std()}")print(f"Medyan: {np.median(veri)}")print(f"Minimum ve Maksimum: {veri.min()} ve {veri.max()}")print(f"Çeyrekler: {np.percentile(veri, [25, 50, 75])}")
Veri: 30,15,40,10,5
Ortalama: 20.0
Varyans: 170.0
Standart Sapma: 13.038404810405298
Medyan: 15.0
Minimum ve Maksimum: 5.0 ve 40.0
Çeyrekler: [10. 15. 30.]
Uyarı
Pandas’ın verdiği standart sapma ile tanımdan elde ettiğimiz standart sapma değerleri farklıdır. Bunun sebebi pandas’ın yansız (unbiased) yaklaşımı kullanmasıdır. Daha ayrıntılı bilgi için [1] numaralı kaynağa bakınız.
Standart Sapma, Pandas: df.std()= 14.577379737113251
Standart Sapma, Numpy: veriNP.std()= 13.038404810405298
Burada pandas ile numpy modüllerinin standart sapma (varyans) değerleri, varsayılan özellikler kullanıldığında aynı sonucu vermez. Bunun sebebi istatistikte “yanlı/yansız (biased/unbiased)” olarak bilinen iki farklı yaklaşım olmasıdır. Bu iki yaklaşımın farklılıkları için aşağıdaki linkleri inceleyebilirsiniz.
Popülasyon üzerinden hesap yapmak istiyorsanız yanlı yaklaşımı, df.std(ddof=0) veya np.std() kullanın.
Örneklem üzerinden hesap yapmak istiyorsanız yansız yaklaşımıdf.std() veya np.std(ddof=1) kullanın.
Rastgele Sayılar
Önce numpy modülü içerisindeki random paketi ile rastgele sayılar üretelim.
np.random.rand(N): \([0,1)\) arasında düzgün olarak (uniformly) N boyutlu rastgele sayı üretir.
np.random.randn(): \(N(0,1)\) arasında standart normal dağılımlı olarak (standard normal distribution) rastgele sayı üretir.
np.random.randint(a,b): \([a,b)\) arasında düzgün olarak (uniformly) rastgele sayı üretir.
import numpy as npprint(f"5 Boyutlu düzgün dağılımlı rastgele sayılar: {np.random.rand(5)}")print(f"5 Boyutlu normal dağılımlı rastgele sayılar: {np.random.randn(5)}")print(f"5 boyutlu 0 ile 10 arasında rastgele tam sayılar: {np.random.randint(0, 10, 5)}")
5 Boyutlu düzgün dağılımlı rastgele sayılar: [0.12267185 0.39598819 0.48212732 0.47526437 0.83541094]
5 Boyutlu normal dağılımlı rastgele sayılar: [-0.47921566 -0.74999316 -2.22282867 0.40560835 -0.84277702]
5 boyutlu 0 ile 10 arasında rastgele tam sayılar: [8 2 7 4 4]
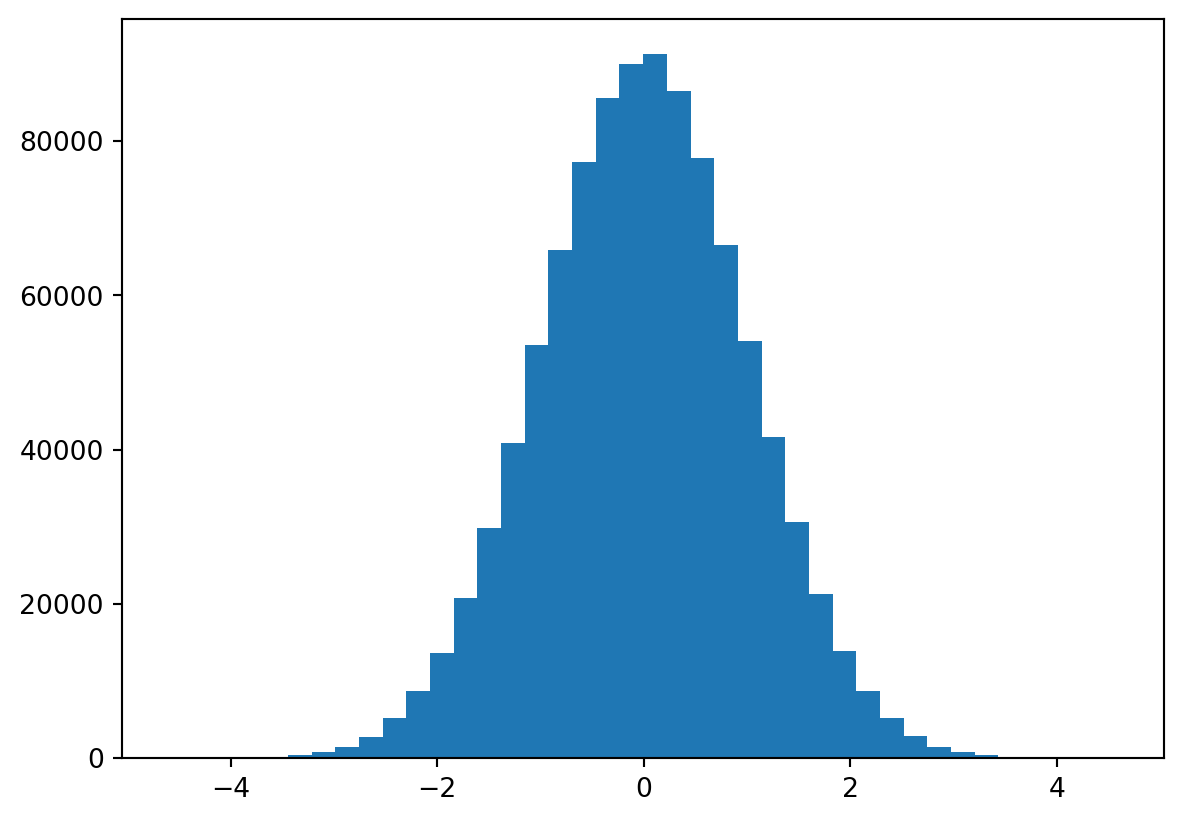
Standart normal dağılımı rastgele sayı üreteci 0’ın ortasında ve 1’in standart sapması olan bir dağılım oluşturur. Bu dağılımın özelliklerini görmek için aşağıdaki kodu çalıştırın.
import numpy as npimport matplotlib.pyplot as plt# 1000 tane rastgele sayı üret#x = np.random.randn(1000)x = np.random.randn(1_000_000)# Histogram çizplt.hist(x, bins=40)plt.show()plt.close()
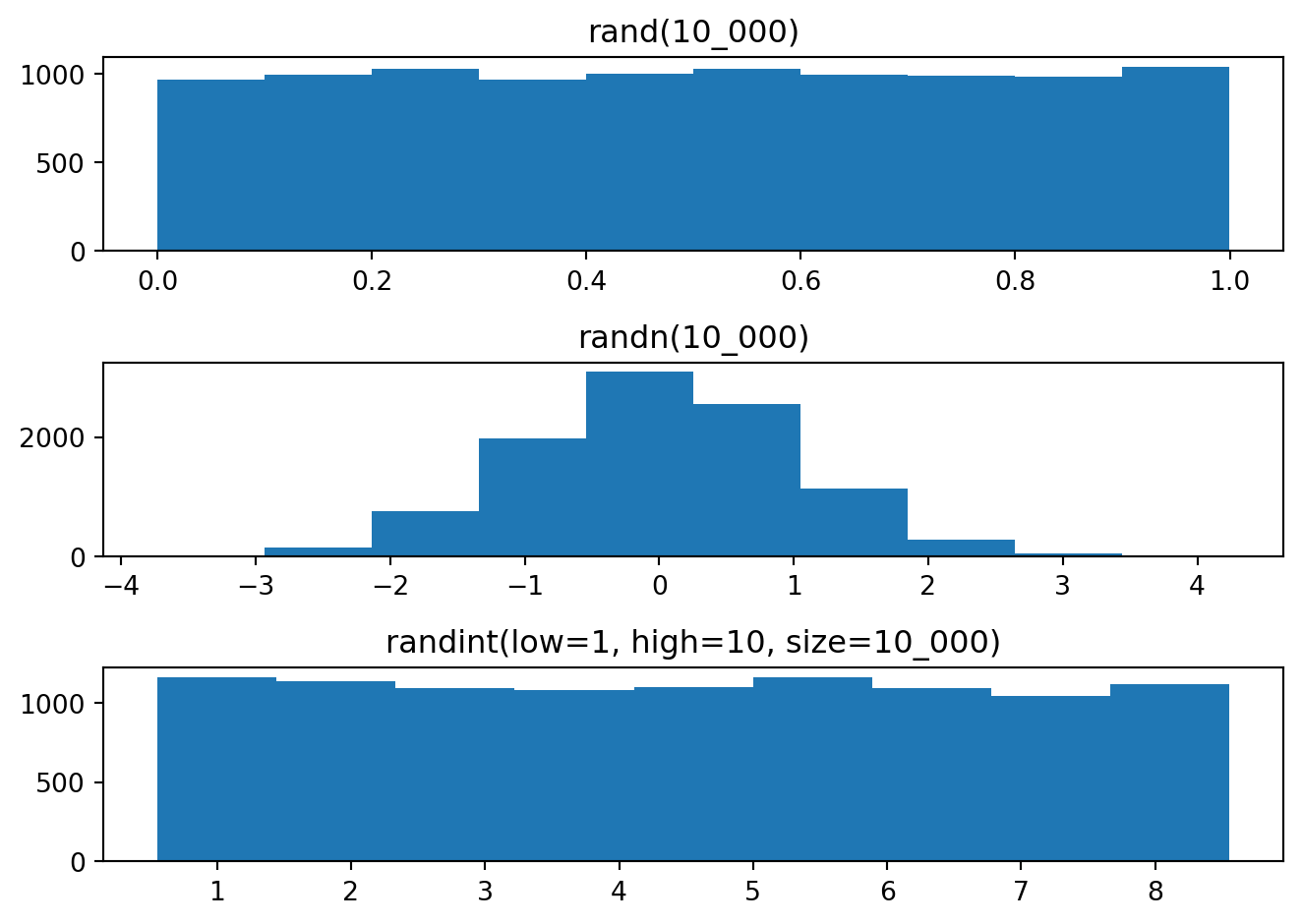
import numpy as npimport matplotlib.pyplot as plt# Rastgele sayı üret [0,1)print(np.random.rand())print("-"*20)# Rastgele 5 tane sayı üret [0,1)print(np.random.rand(5))print("-"*20)# Rastgele 2x4 matris üret [0,1)print(np.random.rand(2, 4))print("-"*20)# Rastgele Normal dağılımlı sayı üretprint(np.random.randn(10))print("-"*20)# Rastgele tam sayı üret [0,10)print(np.random.randint(0, 10))print("-"*20)# Rastgele 5 tane tam sayı üretprint(np.random.randint(0, 10, 5))# print(np.random.randint(low=0, high=10, size=5))print("-"*20)# Rastgele 2x4 matris üret [0,10)print(np.random.randint(0, 10, (2, 4) ))#print(np.random.randint(low=0, high=10, size=(2,4)))# Çizfig, axes = plt.subplots(3,1)axes[0].hist(np.random.rand(10_000))axes[0].set_title("rand(10_000)")axes[1].hist(np.random.randn(10_000))axes[1].set_title("randn(10_000)")axes[2].hist(np.random.randint(low=1, high=10, size=10_000), bins=9, align='left')axes[2].set_title("randint(low=1, high=10, size=10_000)")plt.tight_layout()
İlerleyen bölümlerde belli bir array’den rastgele bir eleman seçmek isteyeceğiz. Bunun için np.random.choice() özelliğini kullanacağız. Eğer replace=False özelliği ile kullanırsak seçilen eleman tekrar seçilemez. Varsayılan özellik replace=True’dur.
import numpy as np# 0 ile 4 arasında 3 tane rastgele sayı seçprint(np.random.choice(5, 3))# Aynı işi np.random.randint(0,5,3) de yaparprint("--"*20+"1")# 0.1, 0, 0.3, 0.6, 0 olasılıkları ile 3 tane rastgele sayı seç.# Yani 0.1 olasılıkla 0, # 0 olasılıkla 1, # 0.3 olasılıkla 2, # 0.6 olasılıkla 3, # 0 olasılıkla 4print(np.random.choice(5, 3, p=[0.1, 0, 0.3, 0.6, 0]))print("--"*20)# Tekrar seçim yapmadan 3 tane rastgele sayı seçprint(np.random.choice(5, 3, replace=False))# Aynı işi np.random.permutation(np.arange(5))[:3] de yaparprint("--"*20)# Harfler arasından 2 tane rastgele isim seçharfler = ['A', 'B', 'C', 'Ç' ,'D', 'E', 'F', 'G', 'Ğ' , 'H']print(np.random.choice(harfler, 2))print(np.random.choice(harfler, 2, replace=False))
Rastgele sayı seçiminde çekirdek (seed) seçimi de önemli bir faktördür çünkü rastgelelik bir çekirdek üzerinden oluşur. Aynı çekirdek seçilir ise “aynı rastgelelik” kullanarak sayılar/seçimler oluşturulur.
Bizim çalışacağımız problemlerde çekirdek seçimi önemli olmayacaktır ancak oyun, simülasyon gibi problemlerde çekirdek seçimi önemli olabilir.
Terraria Seed
Minecraft Seed
Çekirdek seçimi için np.random.seed() fonksiyonunu kullanılır.
Belirlenen bir çekirdek üzerine seçimler yapmak için aşağıdaki gibi bir rastgele durum belirlenir.
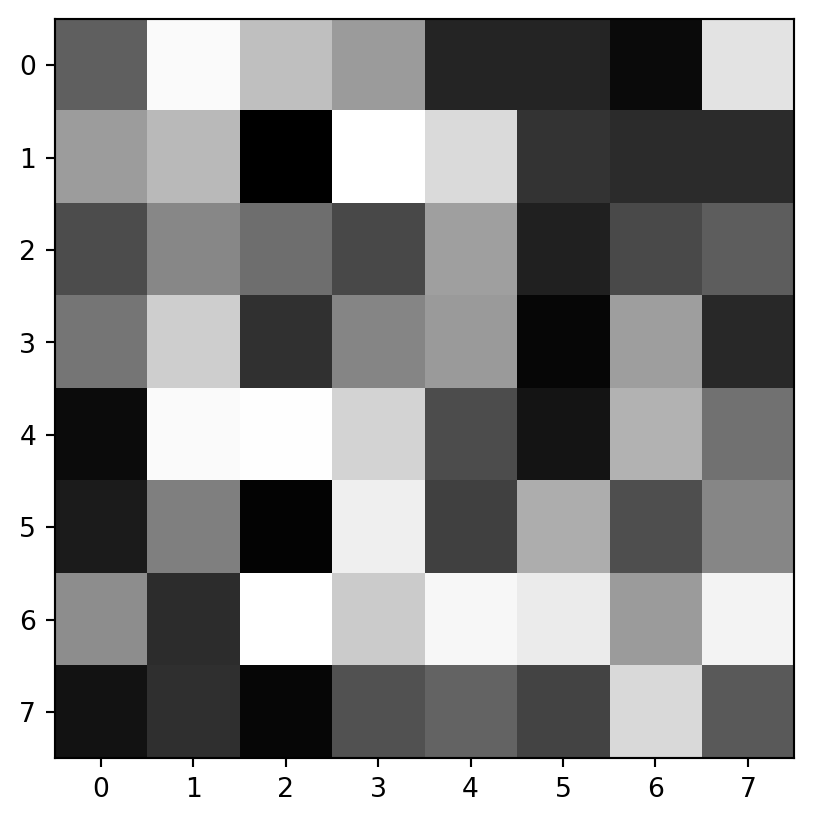
import numpy as npimport matplotlib.pyplot as plt# Oyun Haritası 42 çekirdek kullancekirdekSayisi=42cekirdek= np.random.RandomState(cekirdekSayisi)# 2 boyutlu bir harita olacak şekilde çizdirplt.imshow(cekirdek.rand(8,8), cmap='gray', interpolation='nearest')plt.show()plt.close()print(f"4 adet rastgele sayı: {cekirdek.rand(4)}")print("-"*20)print(f"4 adet rastgele sayı: {cekirdek.rand(4)}")
4 adet rastgele sayı: [0.28093451 0.54269608 0.14092422 0.80219698]
--------------------
4 adet rastgele sayı: [0.07455064 0.98688694 0.77224477 0.19871568]
Yukarıdaki programı tekrar çalıştırdığımızda aynı sonuçları alırız. Çünkü çekirdek aynıdır.
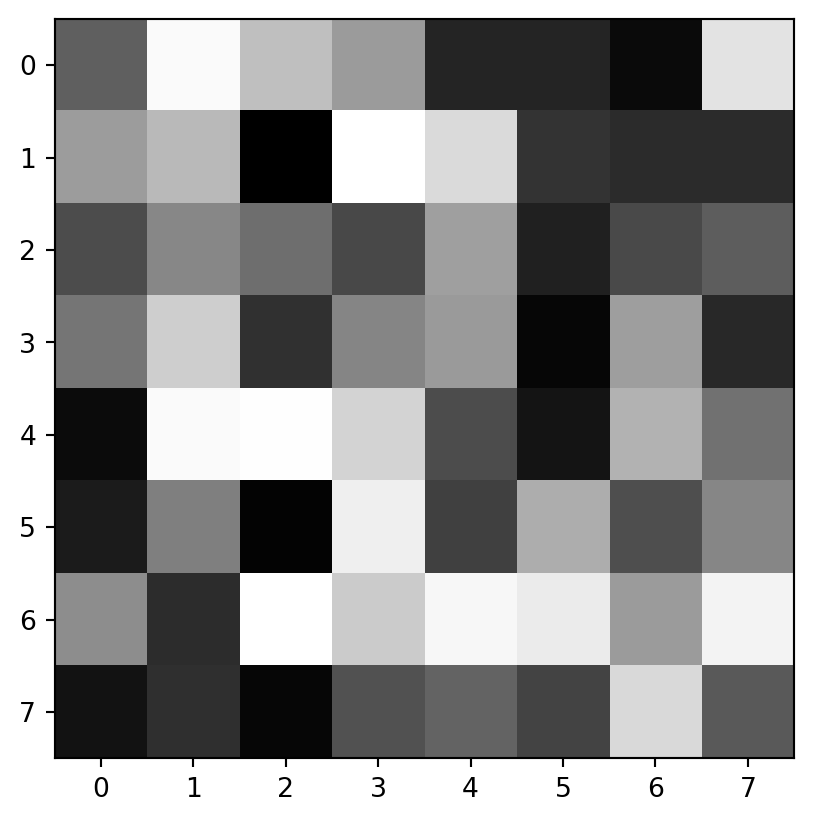
import numpy as npimport matplotlib.pyplot as plt# Oyun Haritası 42 çekirdek kullancekirdekSayisi=42cekirdek= np.random.RandomState(cekirdekSayisi)# 2 boyutlu bir harita olacak şekilde çizdirplt.imshow(cekirdek.rand(8,8), cmap='gray', interpolation='nearest')plt.show()plt.close()print(f"4 adet rastgele sayı: {cekirdek.rand(4)}")print("-"*20)print(f"4 adet rastgele sayı: {cekirdek.rand(4)}")
4 adet rastgele sayı: [0.28093451 0.54269608 0.14092422 0.80219698]
--------------------
4 adet rastgele sayı: [0.07455064 0.98688694 0.77224477 0.19871568]
Rastgele Değişkenler ve Dağılımlar
Popülasyondan rastgele seçilen örneklem üzerinden yapılan istatistiksel incelemelerde, örneklem dağılımının popülasyon dağılımına yakın olması istenir. Bu ve benzeri konular için matematikte olasılık teorisi bulunmaktadır.
Örnek Uzayı (Sample Space): Bir deneyin tüm olası sonuçlarının bir kümesidir.
Örnek uzaydaki tüm elemanlar için bir olasılık değeri vardır.
Olasılık Dağılımı (Probability Distribution): Bir deneyin tüm olası sonuçlarının olasılıklarının bir dağılımıdır.
Rastgele Değişken (Random Variables): Bir deneyin sonucu olarak elde edilen değerlerdir.
Rastgele değişkenlerin birbirinden bağımsız olması gerekir.
Örneğin
Bir paranın örnek uzayı \(\{Yazı,Tura\}\)’dır.
Rastgele değerleri \(\{0,1\}\)’dir.
İstatistiksel işlemler kullanmak için rastgele değişkenlerin olasılık dağılımlarına ihtiyacımız vardır.
Rastgele değişkenler alacağı olası değerler ile karakterize edilir ve bu değerler de olasılık dağılımına göre belirlenir.
En temelde iki çeşit dağılım vardır. 1. Kesikli Dağılımlar, Tam Sayılar (Discrete Distributions) 2. Sürekli Dağılımlar, Gerçel Sayılar (Continuous Distributions)
scipy.stats modülü içerisindeki rv_discrete ve rv_continuous sınıfları ile dağılımların özelliklerine ulaşabiliriz. Bu paketteki metotlar ve açıklamaları için dokümantasyon sayfasına veya Numerical Python kitabında tablo 13-1’e bakabilirsiniz.
Ortalama: 1.0
Median: 1.0
Standart Sapma: 0.5
Varyans: 0.25
Histogramlar
Histogram denildiğinde verinin dağılımdan ve frekansından bahsetmemiz gerekir.
Örneğin:
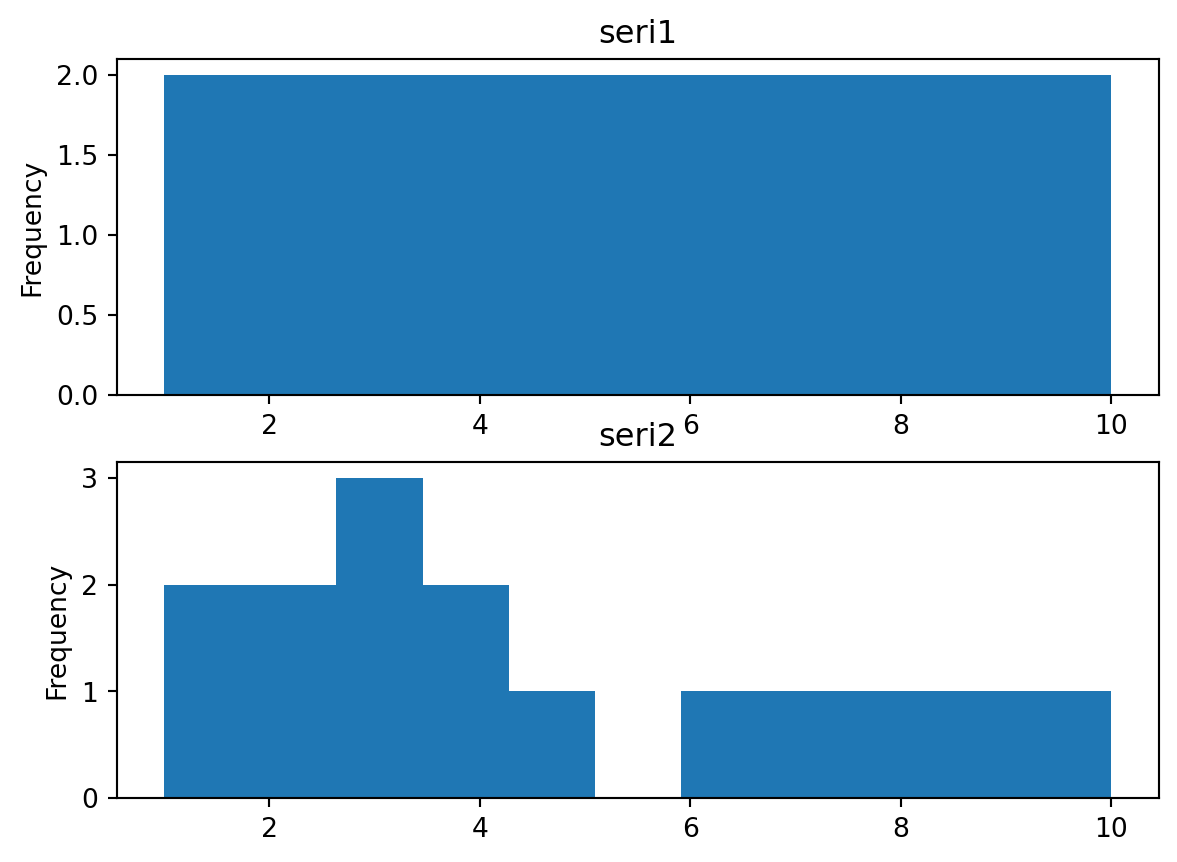
\(1\), \(2\), \(3\), \(4\), \(5\), \(6\) sayıları verimiz olsun. Bu verinin dağılımı tam sayılar arasında eşit olasılıkla dağılmıştır. Yani her sayının gelme olasılığı aynıdır. Bu verinin frekansı yani tekrarlanma sayısı da aynıdır. Çünkü her sayı birer kez tekrar edilmiştir.
\(1\), \(3\), \(3\), \(3\), \(4\), \(6\) sayıları verimiz olsun. Bu verinin dağılımı tam sayılar arasında eşit olasılıkla dağılmamıştır. Yani her sayının gelme olasılığı aynı değildir. \(1\), \(4\) ve \(6\) sayılarının gelme olasılığı \(1/6\), \(3\) sayısının gelme olasılığı \(3/6\)’dır. Bu verinin frekansı yani tekrarlanma sayısı da aynı değildir. Çünkü \(3\) sayısı 3 kez tekrar edilmiştir.
Bu iki örneğin histogramlarını çizelim.
import pandas as pdimport matplotlib.pyplot as plt# Veriseri1= pd.Series([1,2,3,4,5,6,7,8,9,10])seri2= pd.Series([1,1.5,2,2,3,3,3,4,4,5,6,7,8,9,10])# Çizfig, axs= plt.subplots(2,1)seri1.plot(kind="hist", ax=axs[0], title="seri1", bins=5)seri2.plot(kind="hist", ax=axs[1], title="seri2", bins=11)
Bins: Yatay eksendeki sütun sayısı.
Örneğin: 1,2,3,4,5 verisi var ise bin=5 yapıldığında sütunların arası hiç gözükmez, çünkü yatay eksende 1 değerinin üstünde sütun olur, 2 değerinin üstünde sütun olur vs. bin=11 yapıldığında ise kabaca 0.5 üzerinde ve 1 üzerinde sütun çizilmeye çalışılır.
Aşağıdaki linklerden bin sayısı en iyi nasıl seçilir hakkında bilgi alabilirsiniz.
100 adet parayı 1000 kere atan ve np.random.rand() fonksiyonu kullanan bir betik dosyası yazın. Her atıldığında 100 tane paranın kaç tanesi tura geldiğini kaydedin ve sonucu histogram grafiği olarak çizdirin.
Problem 2
Uygulama 1 ile verilen betik dosyasını np.random.choice() fonksiyonu kullanarak yapın.
Problem 3
100 adet zarı 1000 kere atan ve np.random.choice() fonksiyonunu kullanan bir betik dosyası yazın. Her atıldığında 100 tane zarın kaç tanesinin 6 geldiğini, kaç tanesinin 5 geldiğini vs. kaydedin ve sonucu histogram grafiği olarak çizdirin.
600 adet parayı 1000 kere atan bir algoritma oluşturun. 600 adet parnın kaçı tura geldiğini hesaplasın. Bunu 1000 kere yapacak şekilde mofiye edin. 600 tane para atıldığında kaç tanesinin tura geldiğini gösteren bir histogram çizdirin.
Aynı işlemi bu sefer bir zaın 3 gelmesi için yapın. Yani, 600 adet zarı 1000 kere attığınızda, 600 zarın kaç defa 3 geldiğini hesaplayan bir program yazın. 600 tane zar atıldığında kaç tanesinin 3 geldiğini gösteren bir histogram çizdirin.
600 adet zarı ve 600 adet parayı aynı anda yani beraber 1000 kere atıldığında, kaçında 3 ve tura geldiğini hesaplayan bir program yazın. 600 tane para ve zar atıldığında kaç tanesi 3 ve tura geldiğini gösteren bir histogram çizdirin.
Not: 2. sorunun verisini kullanabilirsiniz.
İpucu: Dağılımının \(600\times(1/2)\times(1/6)=50\) etrafında olması beklenir.
Aşağıdaki adımları yapın.
1200 adet (birinci zarı 600 kere ikinci zarı 600 kere düşünün) zarı 1000 kere atıp, ikili toplamları kaç kere 7 geldiğini ve kaç kere 12 geldiğini hesaplayan bir program yazın. 1200 tane zar atıldığında ikili toplamları kaç kere 7 ve kaç kere 12 geldiğini gösteren histogramları aynı figürde çizdirin.
Toplamı 7 ve 12 gelen dağılımlar için aşağıdaki değerleri hesaplayın.
Ortalama değer
Mod (en çok tekrar eden değer)
Standart sapma, Varyans
Medyan
Maksimum ve Minimum değer
İki dağılım için efektif boyutu, Cohen’in d değerini hesaplayın.
İpucu: Algoritmayı şöyle yazabilirsiniz. İki ayrı zarı attım ve toplamları 7 geldi. Bunu 600 kere tekrarladım ve kaydettim. Bu işlemi 1000 kere daha yaptım.
İpucu2: 7’nin dağılımının \(600\times(1/6)=100\) etrafında olması beklenir. (1+6, 2+5, 3+4, 4+3, 5+2, 6+1)
İpucu3: 12’nin dağılımının \(600\times(1/36)=16.7\) etrafında olması beklenir.
İpucu4:
\[
d = \frac{\overline{x}_1 - \overline{x}_2}{s_{havuz}}
\]
Numerical Python: Scientific Computing and Data, Science Applications with Numpy, SciPy and Matplotlib, Robert Johansson, Apress, İkinci Basım, 2019, syf 443